Résoudre les limites de longueur de contexte pour Ollama sur des GPU à faible mémoire#
Vous avez peut-être rencontré un problème où les applications agentiques ne fonctionnent pas comme prévu sur des modèles locaux tournant sur des GPU à « faible mémoire ». Plus précisément, ces applications peuvent devenir extrêmement limitées ou ne même plus répondre en raison de fenêtres de contexte restrictives.
Par exemple, même en utilisant des modèles conçus pour de grands contextes avec des outils comme Hermes, OpenCode ou VS Code, ils peuvent ne pas fonctionner correctement, comme le montrent les captures d'écran suivantes :
| Outil | Capture d'écran (installation Ollama par défaut) |
|---|---|
| Hermes | 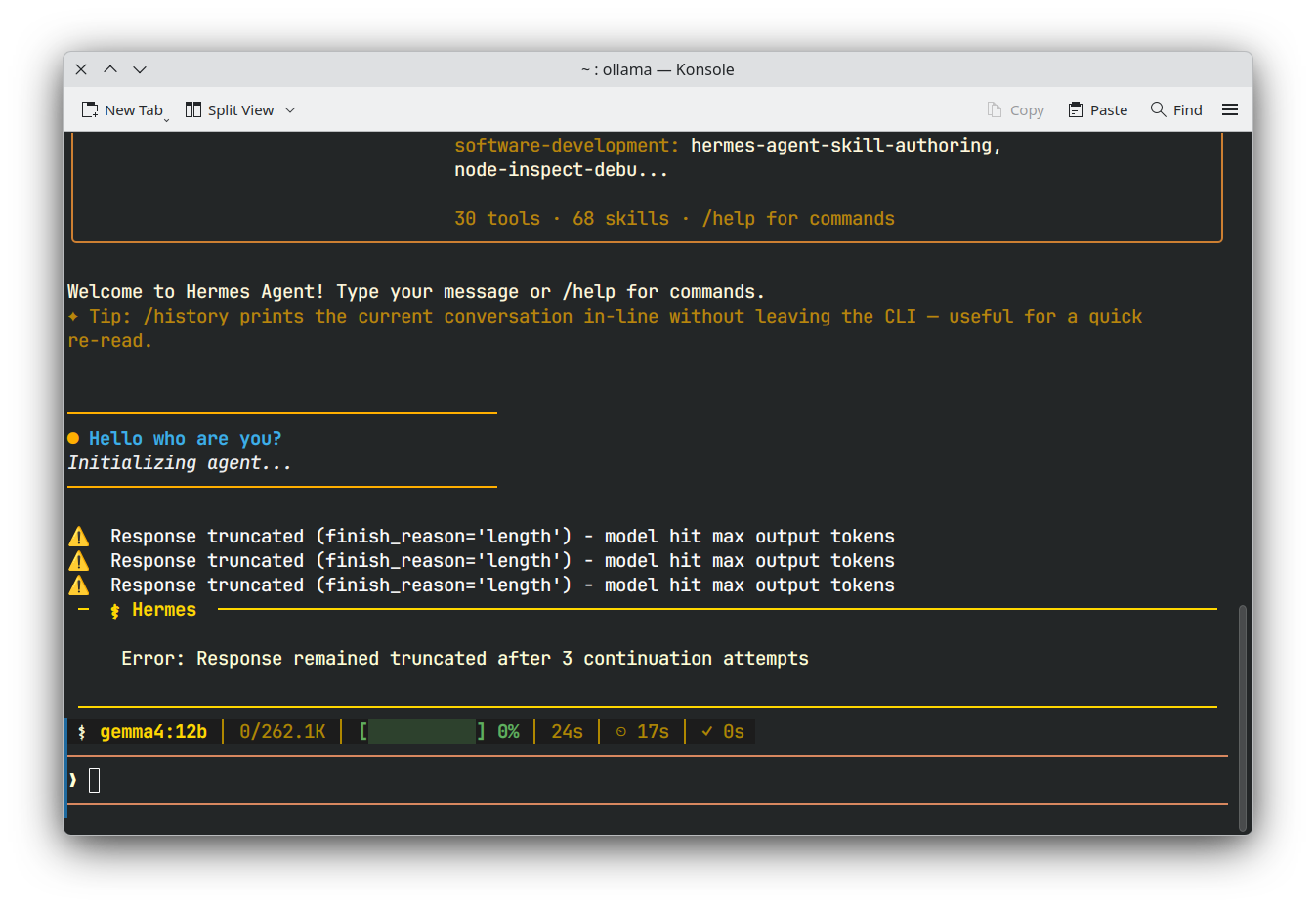 |
| OpenCode | 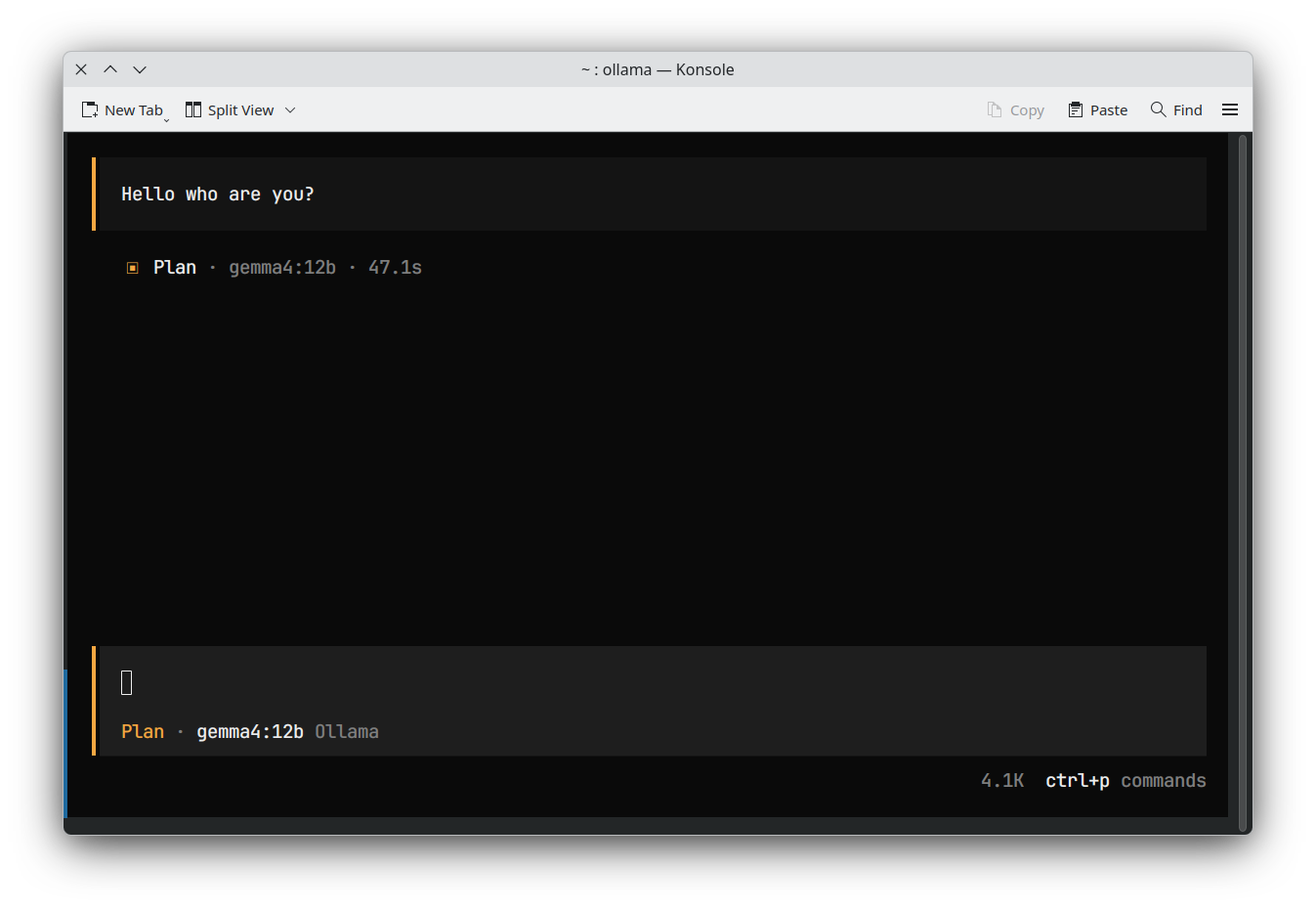 |
| VS Code | 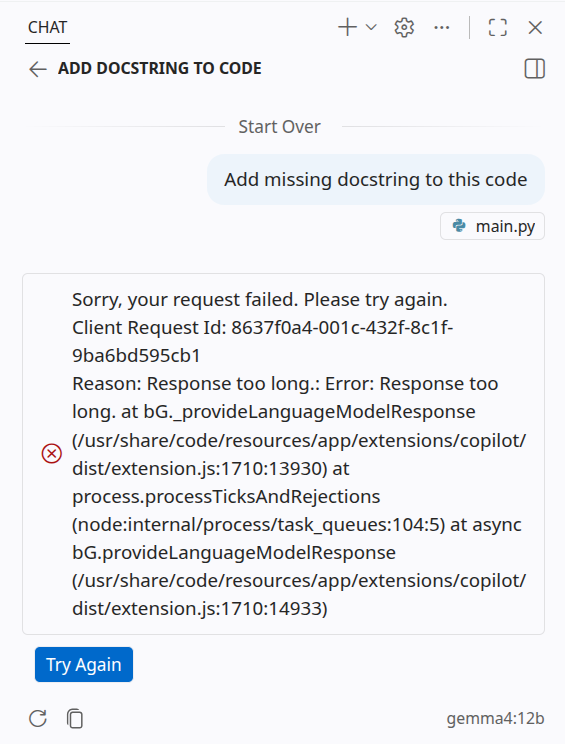 |
Comme vous pouvez le voir, je ne peux pas utiliser gemma4 12b avec l'installation par défaut d'Ollama. Ce problème persiste également pour d'autres modèles qui tiennent sur mon GPU ; dans certains cas, il est même difficile de diagnostiquer ce qui se passe, comme le montre l'exemple d'OpenCode.
J'ai trouvé une solution simple à ce problème sous Linux. Le problème est que la détermination automatique de la taille du contexte par Ollama sur les machines locales est souvent trop prudente. Selon la documentation d'Ollama, si vous avez moins de 24 Go de VRAM, votre contexte maximal pour chaque modèle est par défaut limité à seulement 4k jetons (tokens). C'est bien trop peu pour les modes agentiques, même si les modèles de la famille Gemma 4 (par exemple, e2b, e4b ou 12b) sont capables de gérer des contextes plus importants sur des GPU à faible mémoire.
Pour corriger cela, vous pouvez définir manuellement la longueur du contexte dans votre configuration Ollama. Exécutez la commande suivante pour modifier la configuration du service :
sudo systemctl edit ollama.service
Ensuite, ajoutez les lignes suivantes au fichier :
[Service]
Environment="OLLAMA_CONTEXT_LENGTH=256000"
Note
La valeur de OLLAMA_CONTEXT_LENGTH doit être ajustée en fonction de votre mémoire disponible. Par exemple, si vous avez un GPU avec 4 Go de VRAM, j'ai constaté qu'une limite de 64k semble etre le maximum. Toutefois, c'est toujours une valeur meilleure que le défaut de 4k et permet aux outils agentiques comme Hermes, VS Code et OpenCode de fonctionner nettement mieux.
Après avoir enregistré le fichier, rechargez le démon systemd et redémarrez Ollama :
sudo systemctl daemon-reload
sudo systemctl restart ollama
Enfin, vérifiez que vos modifications ont été correctement appliquées :
sudo systemctl show ollama.service -p Environment
J'ai testé cette configuration avec gemma4 12b sur ma RTX 4060 (8 Go de VRAM), et les résultats étaient exactement comme prévu :
| Outil | Capture d'écran (Ollama corrigé) |
|---|---|
| Hermes | 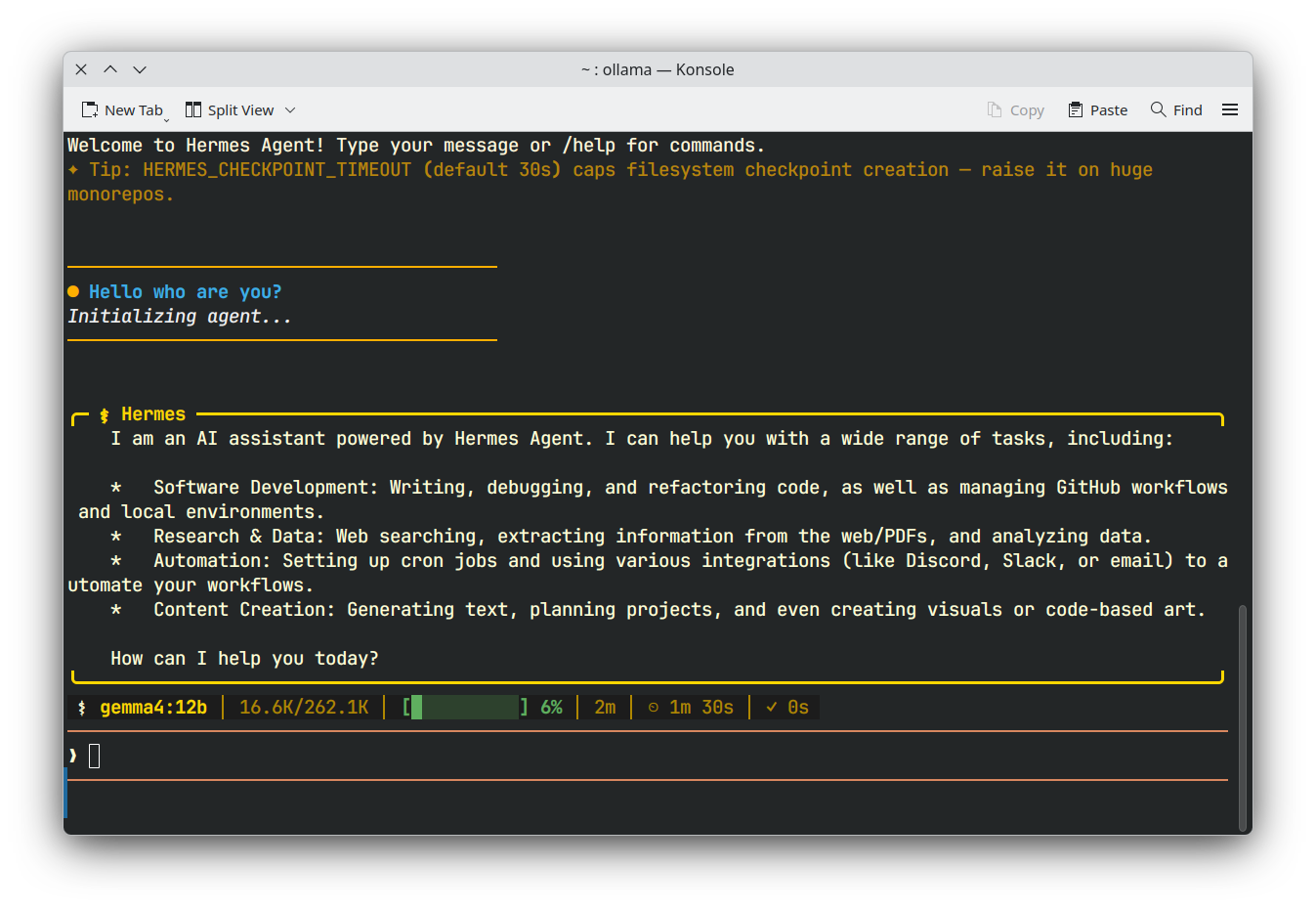 |
| OpenCode | 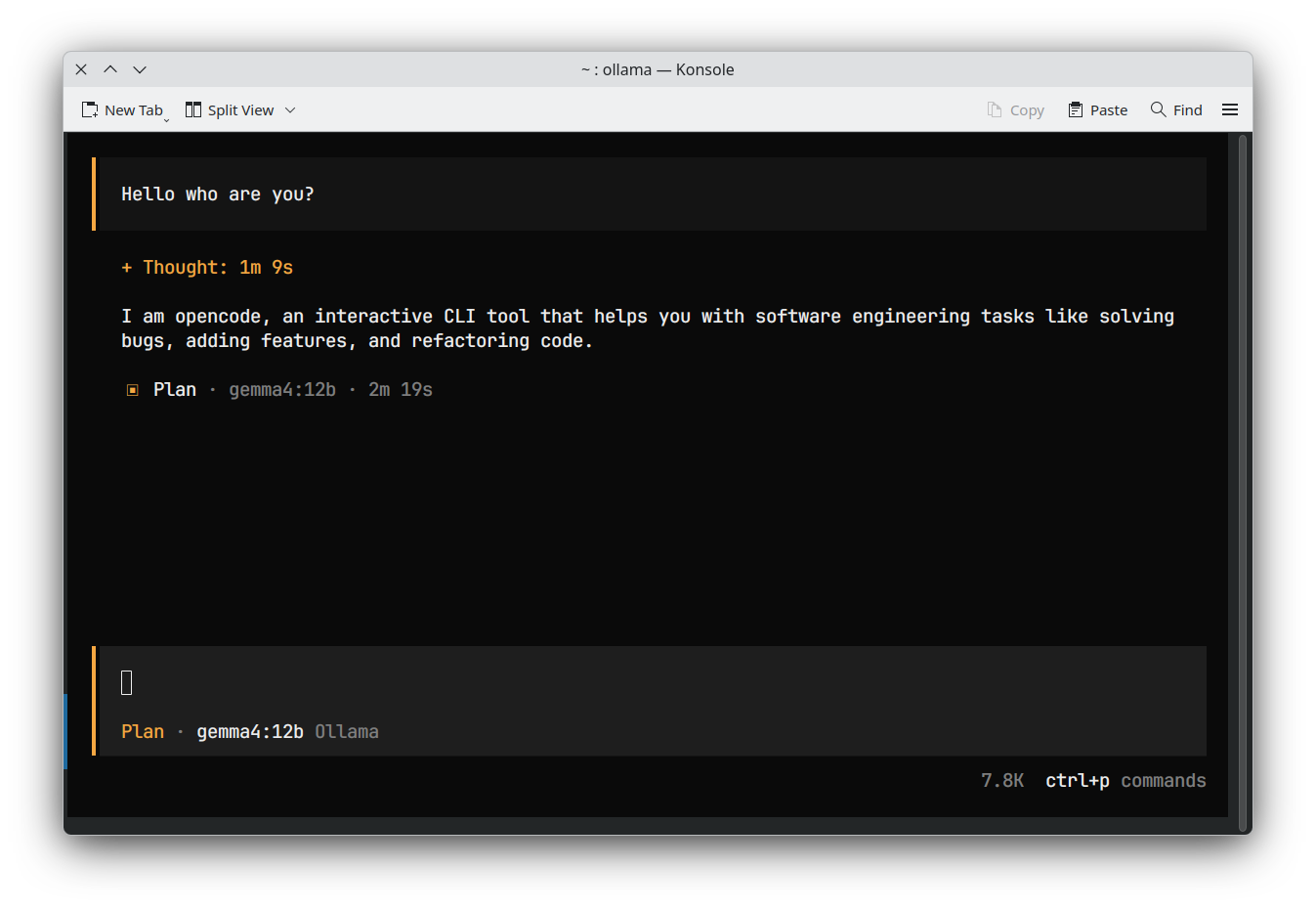 |
| VS Code | 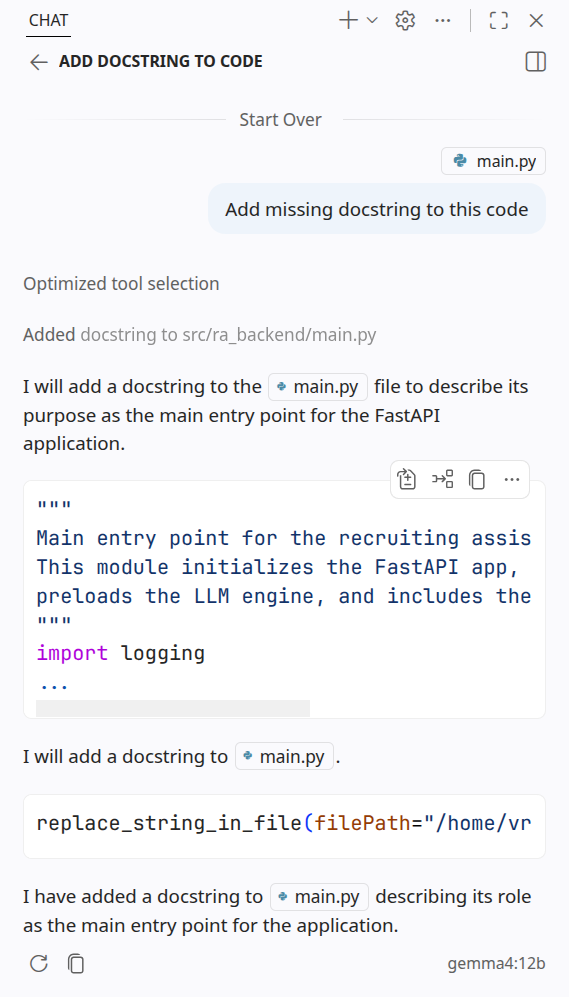 |
Bien que les vitesses d'inférence puissent être plus lentes pour les modèles plus volumineux comme gemma4 12b, je peux désormais l'utiliser avec des applications agentiques !
Pour résoudre ce problème sous Windows ou Mac, vous pouvez aller dans les paramètres de l'application Ollama et modifier directement la taille du contexte.
Merci de m'avoir lu, j'espère que cela vous a été utile et inspirant.
Si vous avez des remarques ou des suggestions, n'hésitez pas à partager vos idées/conseils.